REFUSION: A Diffusion Large Language Model with Parallel Autoregressive Decoding
Artificial Intelligence Large Language ModelsPosted by mhb on 2025-12-23 02:54:29 |
Share: Facebook | Twitter | Whatsapp | Linkedin Visits: 114
Introduction
Large language models are widely used for reasoning, coding, and problem solving. However, most existing systems rely on autoregressive decoding, which generates text one token at a time. This sequential process limits inference speed and reduces the potential for efficient parallelization. Although masked diffusion models enable parallel generation, they often suffer from high computational cost and incoherent outputs due to weak modeling of token dependencies. To overcome these challenges, this paper introduces REFUSION, a diffusion-based language model that combines parallel decoding with autoregressive structure to achieve both high efficiency and strong generation quality.
Methodology
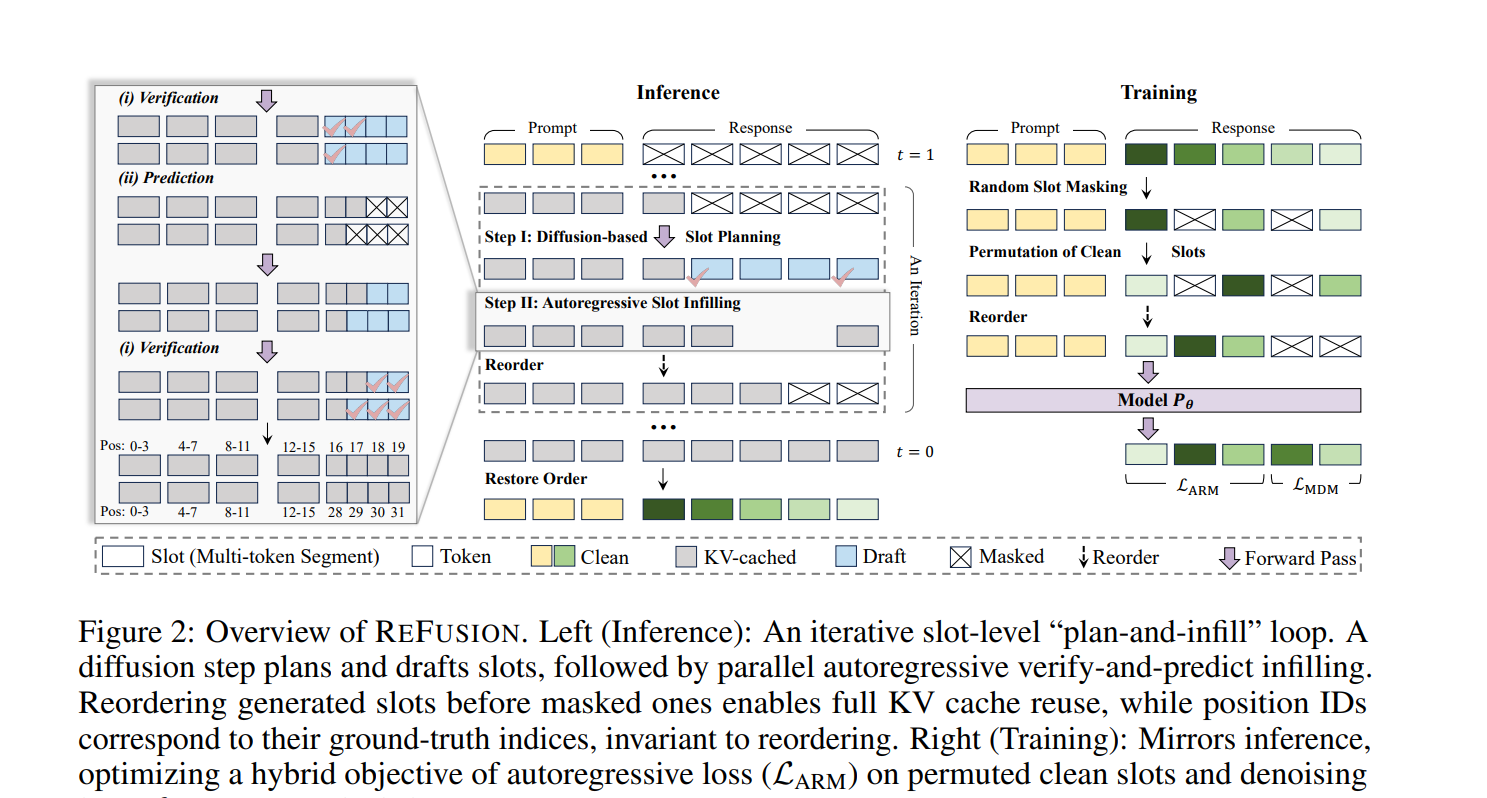
REFUSION adopts a slot-based generation framework in which a sequence is divided into fixed-length contiguous segments called slots. Instead of predicting tokens independently, the model decodes entire slots in parallel while preserving autoregressive decoding within each slot. The approach follows a two-step plan-and-infill process. First, a diffusion-based planner identifies weakly dependent slots suitable for parallel generation. Second, an autoregressive infilling step completes these slots using a causal attention mechanism. This design enables effective reuse of key-value caches, reducing inference overhead while maintaining coherence.
Training Strategy
The training process closely mirrors inference by randomly masking slots and permuting visible slots to simulate non-sequential generation. REFUSION employs a hybrid training objective that combines autoregressive loss for unmasked slots with diffusion denoising loss for masked slots. Unlike conventional diffusion models that learn only from masked tokens, this approach leverages supervision from all tokens, leading to improved data efficiency and more stable training.
Experimental Results
Experiments conducted across multiple benchmarks in mathematics, reasoning, and code generation show that REFUSION significantly outperforms existing masked diffusion models. The model achieves substantial performance improvements along with large inference speedups compared to prior diffusion-based approaches. REFUSION also competes effectively with strong autoregressive models, surpassing them on several tasks while maintaining faster inference, demonstrating its balance of quality and efficiency.
Conclusion
REFUSION offers an effective solution to the trade-off between speed and quality in language generation. By enabling structured parallel decoding at the slot level and integrating diffusion-based planning with autoregressive infilling, the model achieves fast inference, coherent outputs, and efficient training. These results establish REFUSION as a strong advancement in diffusion-based language modeling and highlight structured parallel generation as a promising direction for future large language models.
Search
Categories
Recent News
- Clinical application research on the titanium metal metatarsal prosthesis designed through FEA and manufactured by 3D printing
- Manually weighted taxonomy classifiers improve species-specific rumen microbiome analysis compared to unweighted or average weighted taxonomy classifiers
- A deep learning based smartphone application for early detection of nasopharyngeal carcinoma using endoscopic images
- sCIN: a contrastive learning framework for single-cell multi-omics data integration
- CustOmics: A versatile deep-learning based strategy for multi-omics integration
- Tracking temporal progression of benign bone tumors through X-ray based detection and segmentation
- mCNN-GenEfflux: enhanced predicting Efflux protein and their super families by using generative proteins combined with multiple windows convolution neural networks
- Evaluation of normalized T1 signal intensity obtained using an automated segmentation model in lower leg MRI as a potential imaging biomarker in Charcot– Marie–Tooth disease type 1A
Popular Paper
- sCIN: a contrastive learning framework for single-cell multi-omics data integration
- CustOmics: A versatile deep-learning based strategy for multi-omics integration
- A deep learning based smartphone application for early detection of nasopharyngeal carcinoma using endoscopic images
- Tracking temporal progression of benign bone tumors through X-ray based detection and segmentation
- Clinical application research on the titanium metal metatarsal prosthesis designed through FEA and manufactured by 3D printing