T5Gemma 2: Seeing, Reading, and Understanding Longer
Artificial Intelligence Large Language ModelsPosted by mhb on 2025-12-23 02:55:53 |
Share: Facebook | Twitter | Whatsapp | Linkedin Visits: 98
Introduction
Modern large language models are expected to read, reason, and understand information across long contexts and multiple modalities such as text and images. While decoder-only architectures have achieved strong performance, they often struggle with efficient long-context handling and multimodal understanding. Encoder–decoder models offer architectural advantages, but have lagged behind in scale and capability. To address this gap, this paper introduces T5Gemma 2, a new family of lightweight encoder–decoder models designed for multilingual, multimodal, and long-context understanding with improved efficiency and performance.
Methodology
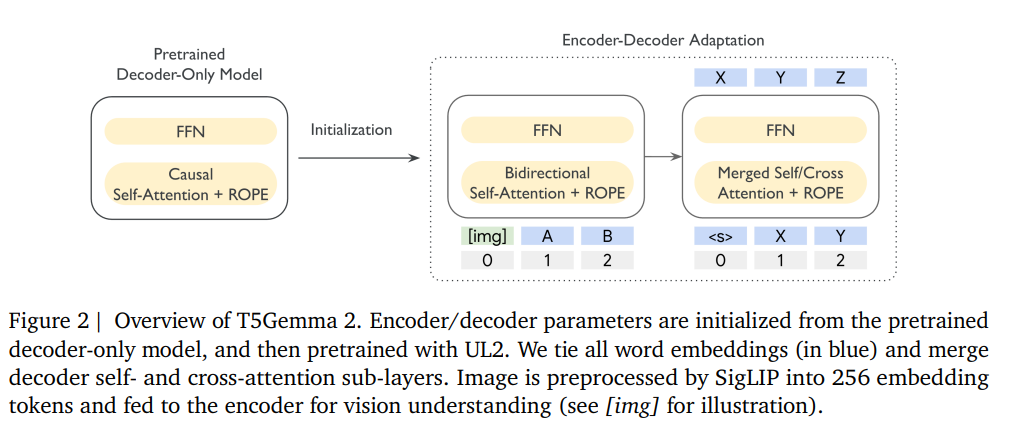
T5Gemma 2 adapts pretrained decoder-only models into encoder–decoder architectures using a unified training strategy. The model extends text-only systems to multimodal inputs by incorporating a frozen vision encoder that feeds image representations directly into the encoder. To improve efficiency, the architecture introduces tied word embeddings shared across the encoder and decoder, as well as merged attention that unifies decoder self-attention and cross-attention into a single mechanism. These design choices reduce parameter redundancy while preserving modeling capacity.
Training Strategy
The models are pretrained on large-scale multilingual text, code, mathematical data, and images using a unified learning objective. Training supports long input and output sequences, enabling the model to generalize to contexts far longer than those seen during pretraining. Lightweight post-training through instruction tuning further enhances downstream performance without heavy reinforcement learning or extensive fine-tuning.
Experimental Results
Across a wide range of benchmarks covering reasoning, coding, multilingual understanding, multimodal tasks, and long-context evaluation, T5Gemma 2 demonstrates competitive or superior performance compared to decoder-only counterparts. The results show particularly strong gains in multimodal understanding and long-context tasks, highlighting the benefits of the encoder–decoder architecture even at relatively small model sizes.
Conclusion
T5Gemma 2 demonstrates that encoder–decoder language models can achieve strong multimodal and long-context performance while remaining efficient and lightweight. By adapting decoder-only models with architectural simplifications such as tied embeddings and merged attention, the approach narrows the gap between efficiency and capability. This work positions T5Gemma 2 as a powerful foundation for future research in multimodal, multilingual, and long-context language modeling.
Search
Categories
Recent News
- Clinical application research on the titanium metal metatarsal prosthesis designed through FEA and manufactured by 3D printing
- Manually weighted taxonomy classifiers improve species-specific rumen microbiome analysis compared to unweighted or average weighted taxonomy classifiers
- A deep learning based smartphone application for early detection of nasopharyngeal carcinoma using endoscopic images
- sCIN: a contrastive learning framework for single-cell multi-omics data integration
- CustOmics: A versatile deep-learning based strategy for multi-omics integration
- Tracking temporal progression of benign bone tumors through X-ray based detection and segmentation
- mCNN-GenEfflux: enhanced predicting Efflux protein and their super families by using generative proteins combined with multiple windows convolution neural networks
- Evaluation of normalized T1 signal intensity obtained using an automated segmentation model in lower leg MRI as a potential imaging biomarker in Charcot– Marie–Tooth disease type 1A
Popular Paper
- sCIN: a contrastive learning framework for single-cell multi-omics data integration
- CustOmics: A versatile deep-learning based strategy for multi-omics integration
- A deep learning based smartphone application for early detection of nasopharyngeal carcinoma using endoscopic images
- Tracking temporal progression of benign bone tumors through X-ray based detection and segmentation
- Clinical application research on the titanium metal metatarsal prosthesis designed through FEA and manufactured by 3D printing