Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Artificial Intelligence Large Language ModelsPosted by mhb on 2025-12-23 02:58:44 |
Share: Facebook | Twitter | Whatsapp | Linkedin Visits: 145
Introduction
Recent progress in video generation has accelerated the development of unified audio-visual generation systems. While earlier models focused primarily on visual quality, the lack of tight audio-visual synchronization limited their practical use in real production scenarios. To address this challenge, this paper presents Seedance 1.5 Pro, a foundation model designed for native joint audio-video generation. The model aims to produce coherent, synchronized, and expressive audio-visual content suitable for professional creative workflows.
Methodology
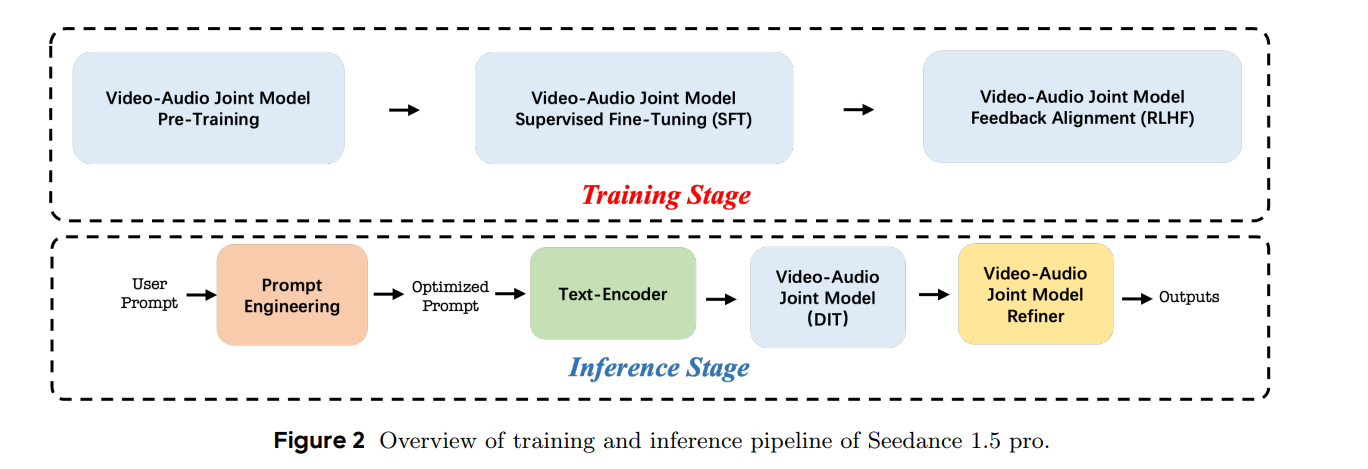
Seedance 1.5 Pro is built on a dual-branch Diffusion Transformer architecture that enables deep interaction between audio and visual modalities. A unified joint generation framework allows the model to handle tasks such as text-to-video-audio and image-guided video-audio synthesis. The architecture integrates a cross-modal joint module that ensures precise temporal alignment and semantic consistency between sound and visuals, while supporting complex motion dynamics and cinematic camera control.
Training Strategy
The model is trained using a comprehensive multi-stage data pipeline that emphasizes audio-visual coherence, motion expressiveness, and curriculum-based learning. High-quality datasets are used for supervised fine-tuning to improve realism and fidelity. Reinforcement learning from human feedback further refines performance using multi-dimensional reward models that evaluate visual quality, motion realism, audio clarity, and synchronization. Additional infrastructure optimizations significantly improve training efficiency.
Experimental Results
Experimental evaluations demonstrate that Seedance 1.5 Pro achieves strong performance across video and audio benchmarks. The model shows notable improvements in motion quality, visual aesthetics, audio expressiveness, and lip-sync accuracy, particularly in multilingual and dialect-rich scenarios. Compared to competing systems, Seedance 1.5 Pro delivers superior audio-visual synchronization and enhanced narrative coherence, while benefiting from over ten-times faster inference through optimized acceleration techniques.
Conclusion
Seedance 1.5 Pro represents a major step forward in native audio-visual joint generation. By combining a unified multimodal architecture with high-quality training and efficient inference optimization, the model successfully balances realism, synchronization, and creative control. These advancements position Seedance 1.5 Pro as a powerful foundation for professional-grade content creation and highlight the growing potential of fully integrated audio-visual generative models.
Search
Categories
Recent News
- Clinical application research on the titanium metal metatarsal prosthesis designed through FEA and manufactured by 3D printing
- Manually weighted taxonomy classifiers improve species-specific rumen microbiome analysis compared to unweighted or average weighted taxonomy classifiers
- A deep learning based smartphone application for early detection of nasopharyngeal carcinoma using endoscopic images
- sCIN: a contrastive learning framework for single-cell multi-omics data integration
- CustOmics: A versatile deep-learning based strategy for multi-omics integration
- Tracking temporal progression of benign bone tumors through X-ray based detection and segmentation
- mCNN-GenEfflux: enhanced predicting Efflux protein and their super families by using generative proteins combined with multiple windows convolution neural networks
- Evaluation of normalized T1 signal intensity obtained using an automated segmentation model in lower leg MRI as a potential imaging biomarker in Charcot– Marie–Tooth disease type 1A
Popular Paper
- sCIN: a contrastive learning framework for single-cell multi-omics data integration
- CustOmics: A versatile deep-learning based strategy for multi-omics integration
- A deep learning based smartphone application for early detection of nasopharyngeal carcinoma using endoscopic images
- Tracking temporal progression of benign bone tumors through X-ray based detection and segmentation
- Clinical application research on the titanium metal metatarsal prosthesis designed through FEA and manufactured by 3D printing