Evaluating Large Language Models in Scientific Discovery
Artificial Intelligence Large Language ModelsPosted by mhb on 2025-12-23 03:00:53 |
Share: Facebook | Twitter | Whatsapp | Linkedin Visits: 201
Introduction
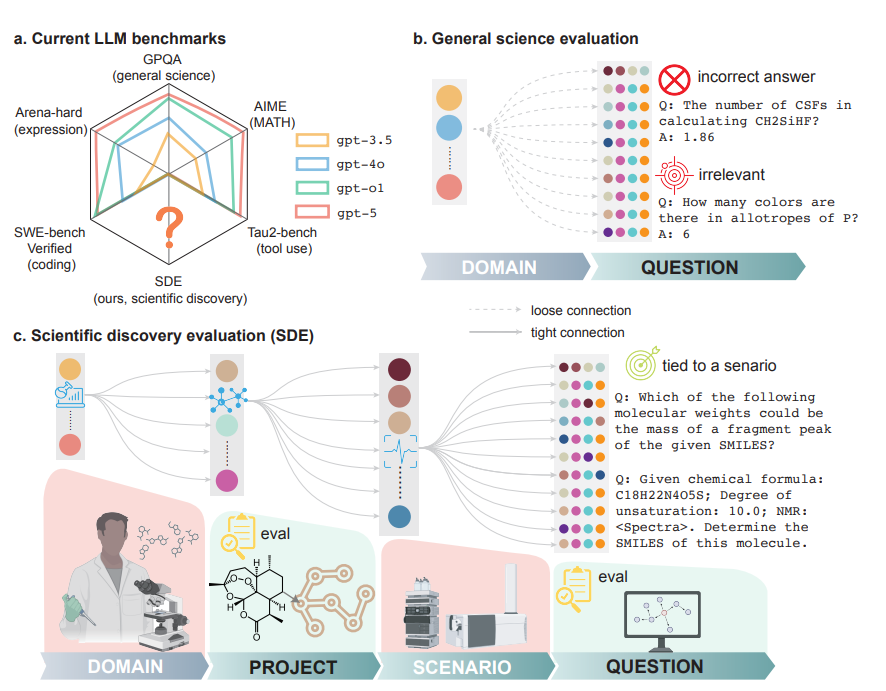
Large language models are increasingly used to support scientific research tasks such as literature review, hypothesis generation, simulation design, and data interpretation. Despite this growing role, most existing science benchmarks evaluate isolated question answering and fail to capture the iterative, context-dependent nature of real scientific discovery. As a result, high benchmark scores do not necessarily reflect a model’s ability to contribute meaningfully to research workflows. This paper addresses this gap by proposing a new evaluation paradigm that measures large language models within realistic scientific discovery settings.
Methodology
The paper introduces the Scientific Discovery Evaluation framework, which grounds evaluation in real research projects across biology, chemistry, materials science, and physics. Each project is decomposed into modular research scenarios, and each scenario generates expert-validated questions tightly connected to practical scientific tasks. The framework evaluates models at two levels: question-level accuracy within scenarios and project-level performance where models must generate hypotheses, run simulations or experiments, and interpret results in an iterative discovery loop.
Training and Evaluation Strategy
Models are evaluated using a standardized harness that supports both static question answering and multi-step project execution. Question-level evaluation measures scenario-specific reasoning accuracy, while project-level evaluation assesses a model’s ability to iteratively refine hypotheses and navigate complex research workflows. The framework enables longitudinal comparison across models, reasoning settings, and scaling regimes, revealing how performance evolves with increased reasoning effort and model size.
Experimental Results
Results show a consistent performance gap between traditional general-science benchmarks and the proposed discovery-grounded evaluation. While state-of-the-art models perform well on decontextualized benchmarks, their accuracy drops significantly in realistic research scenarios. The study also finds diminishing returns from scaling model size and test-time reasoning, as well as strong correlations in failure patterns across leading models. At the project level, no single model dominates across all tasks, and success often depends on the ability to explore hypothesis spaces rather than precise factual knowledge alone.
Conclusion
This work demonstrates that existing benchmarks are insufficient for evaluating large language models in scientific discovery contexts. By introducing a scenario-grounded, multi-level evaluation framework, the paper reveals critical limitations in current models and highlights the skills required for genuine research assistance. The findings suggest that future progress will require targeted training focused on hypothesis generation, iterative reasoning, and tool-integrated workflows. Overall, the proposed framework provides a more faithful and practical measure of readiness for scientific discovery.
Search
Categories
Recent News
- Clinical application research on the titanium metal metatarsal prosthesis designed through FEA and manufactured by 3D printing
- Manually weighted taxonomy classifiers improve species-specific rumen microbiome analysis compared to unweighted or average weighted taxonomy classifiers
- A deep learning based smartphone application for early detection of nasopharyngeal carcinoma using endoscopic images
- sCIN: a contrastive learning framework for single-cell multi-omics data integration
- CustOmics: A versatile deep-learning based strategy for multi-omics integration
- Tracking temporal progression of benign bone tumors through X-ray based detection and segmentation
- mCNN-GenEfflux: enhanced predicting Efflux protein and their super families by using generative proteins combined with multiple windows convolution neural networks
- Evaluation of normalized T1 signal intensity obtained using an automated segmentation model in lower leg MRI as a potential imaging biomarker in Charcot– Marie–Tooth disease type 1A
Popular Paper
- sCIN: a contrastive learning framework for single-cell multi-omics data integration
- CustOmics: A versatile deep-learning based strategy for multi-omics integration
- A deep learning based smartphone application for early detection of nasopharyngeal carcinoma using endoscopic images
- Tracking temporal progression of benign bone tumors through X-ray based detection and segmentation
- Clinical application research on the titanium metal metatarsal prosthesis designed through FEA and manufactured by 3D printing